Deployment Patterns
Gloo Gateway has a very flexible architecture and can be deployed in many ways on various infrastructure stacks. We recommend using Kubernetes, if that is your platform of choice, because it simplifies operations. Kubernetes, however, is not the only way to deploy Gloo Gateway. You can deploy and manage Gloo Gateway on any infrastructure (think VMs, or other container orchestrators) with out of the box support for Consul as the configuration backend.
You may be asking yourself, what options make sense for which problems? In this document we will be looking at the following deployment architectures for Gloo Gateway:
- Simple ingress to Kubernetes
- Kube-native edge API Gateway for Kubernetes
- Sharded API Gateway
- Bounded-context API Gateway
- API Gateway for a service mesh
- Ingress for multi-tentant clusters
- API Gateway in OpenShift
- Across multiple clusters
Let’s dig a bit deeper and see why you might use some of these architectures.
Simple ingress to Kubernetes
Gloo Gateway can play the role of a very simple Kubernetes Ingress Controller. See the docs for setting up Gloo Gateway as an Ingress controller. In this mode, you get a simple HTTP proxy based on Envoy Proxy (restricted by the Kubernetes Ingress API) that can interpret the Ingress spec. Note: a large portion of the Envoy (and Gloo Gateway) functionality is not exposed through the Ingress API. Consider using gateway mode for non-trivial deployments.
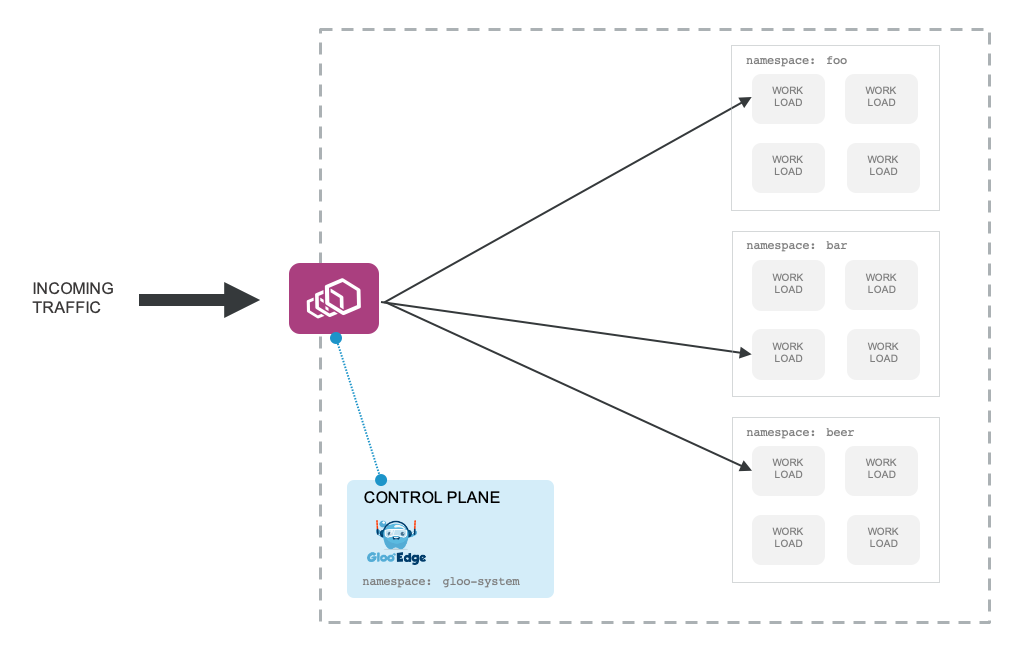
In this deployment model, the only component from the Gloo Gateway control plane that’s required is the gloo deployment. Take a look at the Gloo Gateway Ingress Installation docs for more.
Kube-native edge API Gateway for Kubernetes
Since the Kubernetes Ingress API is very limited and restricted to HTTP traffic, we recommend avoiding it for anything but very trivial hello-world usecases. For any non-trivial cluster, you’ll want to use Gloo Gateway’s Gateway custom resource functionality. In this model, the proxy is deployed as a full-featured API gateway with functionality like traffic routing, header matching, rate limiting, security features (WAF, Oauth, etc) and others. Having these features close to the applications is desirable, therefore you run the Gateway within the cluster as the edge ingress proxy (note, this is ingress with a lowercase “i” and not necessarily the Kubernetes Ingress resource.)
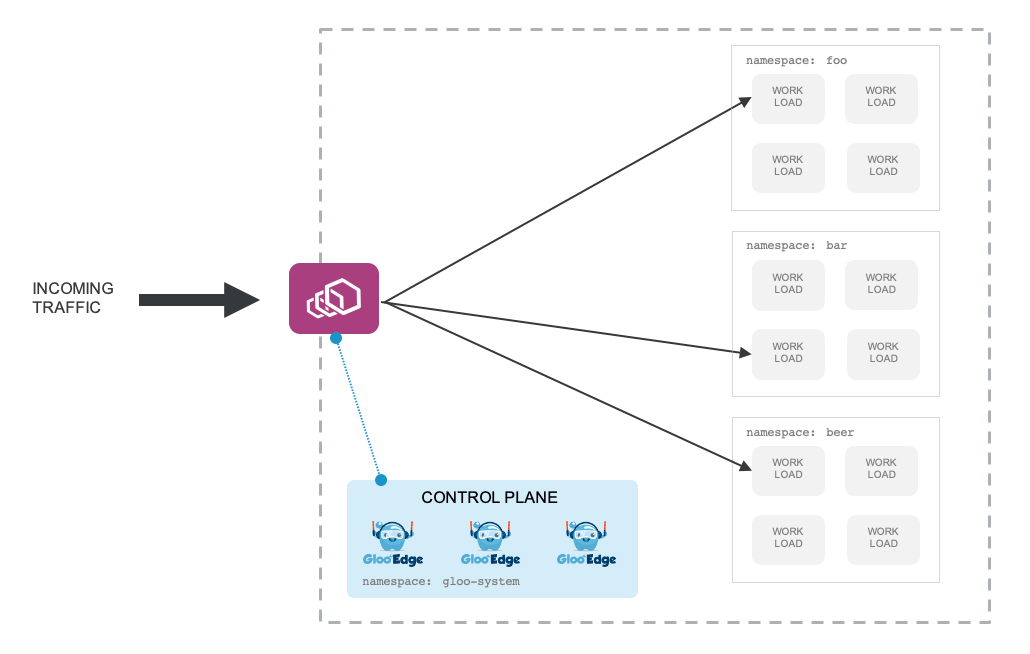
In this model, the gloo, and gateway components of the control plane are required. You will probably see a discovery component as well since that handles all of the automatic service discovery (from endpoints like Kubernetes, Consul, EC2, Lambda, etc). Please see this blog for more information on the identity crisis with ingress controllers, API management, and cloud-native API gateways.
Sharded API Gateway
Sometimes, you’ll want to isolate against the “noisy neighbor” problem in your API infrastructure. For example, you may have a few high-traffic APIs and some low-traffic ones where it’s possible the low-traffic APIs are very valuable and should not be starved by the higher-traffic ones. In this scenario, it makes sense to split up the traffic through different proxies. We can share a single control plane across all of the sharded proxies in this architecture.
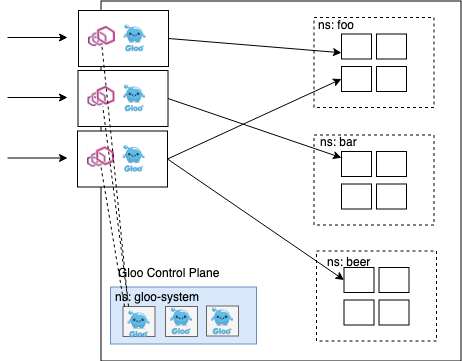
In the above architecture, we can expose the sharded proxies directly to the edge of the proxy. We may rely on separate IP addresses and DNS to perform this sharding. We could try avoid doing this by introducing a single gateway at the edge which is responsible for simple routing while offloading any other API gateway functionality to the second layer of proxies.
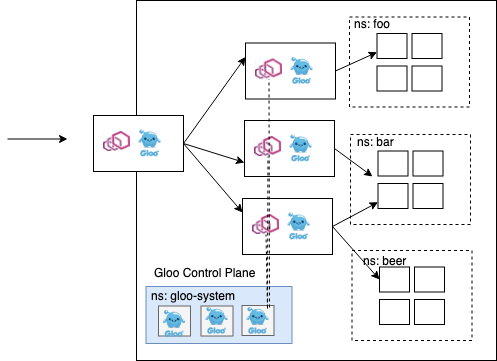
Envoy already has a way to safely isolate calls upstream by using circuit breaking but sharding the calls across multiple proxies enables a higher-degree of isolation for certain APIs that need it.
Bounded-context API Gateway
A variation of the previous deployment pattern of sharding the gateway is by explicitly creating “API Products” or a boundary around certain sets of services and exposing them to the rest of the collaborators through these defined interfaces. The alternative to this is to expose every service to every other service and from a conceptual and maintenance perspective, this ends up being highly untenable. Using the bounded-context API gateway deployment pattern, we can give teams specific control over how their services and APIs are exposed to the rest of the architecture, especially if they opt to use newer protocols like gRPC.
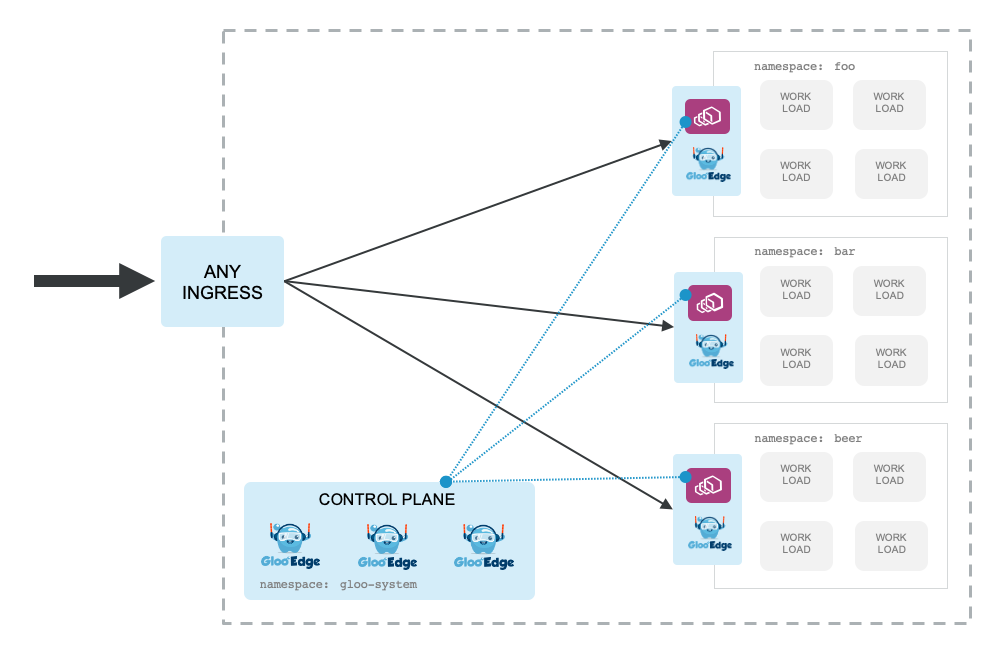
In this model, the proxy sits close to its boundary of services and shares a single control plane with the rest of the cluster. Each group of services is self-managed by that group and enforces the idea of decentralizing these operations. This helps scale out the ability to make changes independently and the Gloo Gateway API specifically supports this (through API delegation).
API Gateway for a service mesh
A service mesh uses proxies (including Envoy) to build a network of L7 connectivity where it solves for issues like application-network observability, security, and resilience. These proxies are typically used to solve these challenges in a so-called “east-west” traffic manner. Just like we’ve seen in the previous deployment pattern, however, we know we will want to provide strict boundaries around our microservices and be very opinionated (and decoupled from implementation) about how it gets exposed to the outside world. This includes ingress and egress from the service mesh. An API Gateway built on Envoy, like Gloo Gateway, can be deployed very complementary to a service mesh and solve these API challenges. Many times, a Gateway built on Envoy Proxy can be a stepping stone to get to service mesh.
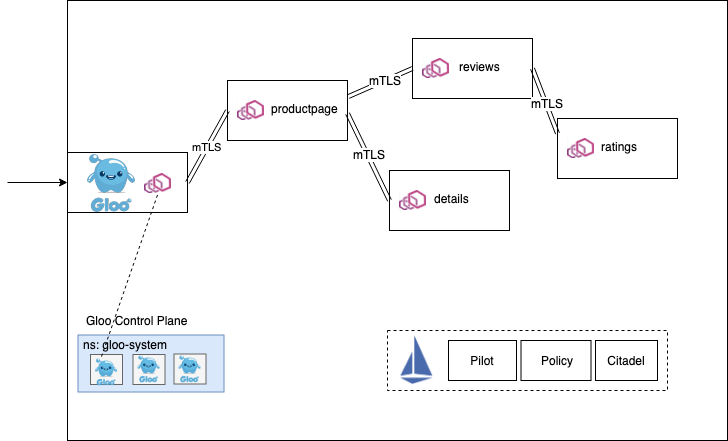
A service mesh doesn’t inherently solve (nor should it) API-level challenges. Things like Web Application Firewall, domain-specific rate limiting, Oauth AuthZ/N, request transformation, etc don’t belong in the service mesh. Gloo Gateway helps fill those gaps.
Ingress for multi-tenant clusters like OpenShift
OpenShift environments, when multi-tenancy is enabled, don’t allow traffic across namespaces directly except through well known egress/ingress points (typically controlled by multi-tenant SDN or network policy). In some cases, traffic destined for another service inside the cluster is forced out of the cluster, to external load balancers or API Management software, and back into the cluster.
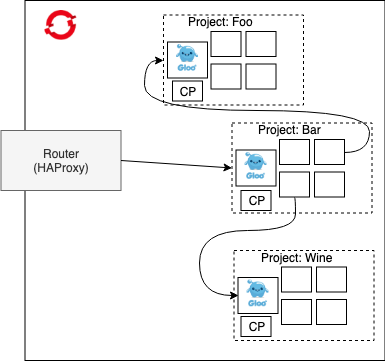
In this scenario, each proxy would have its own API Gateway configurations and be controlled by each team. We have access to the full feature set of an API Gateway like rate limiting, authZ/N, caching, traffic routing/splitting, etc. and fits nicely within a locked down namespaces. Notice how this starts to form a simple routing mesh within the cluster but is configured and controlled by respective project teams, not a centralized configuration store. This approach gives a lot of flexibility and team ownership to the API Gateway with minimal contention points within the organization.
API Gateway in OpenShift
OpenShift comes out of the box with a Router component which is the main ingress point to the cluster. This Router is based on HAProxy and basically acts as a L4 reverse proxy and connection load balancer. It can do TLS termination and collect basic metrics. For a basic deployment of Gloo Gateway, we can add it behind the OpenShift Router.
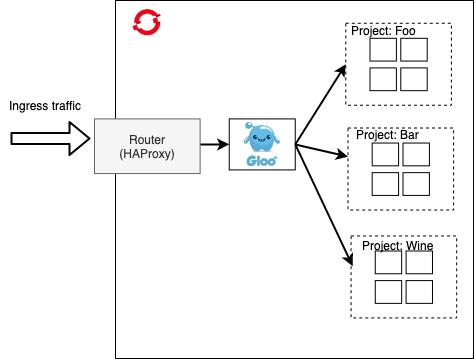
In this scenario, although we’re taking an additional hop, we get access to API Gateway functionality like end-user authentication/authorization, request caching, request/response transformation, etc and important L7 network control for doing things like traffic shadowing, traffic shifting and canary deployments.
Alternatively to running behind the OpenShift Router, we could run Gloo Gateway on infrastructure nodes as NodePort. This has the advantage of directly exposing the API Gateway and eliminating the HAProxy hop, but has the drawback that network folks don’t typically like NodePort. You could also use something like BGP routing or metallb to expose Gloo Gateway through a LoadBalancer directly.
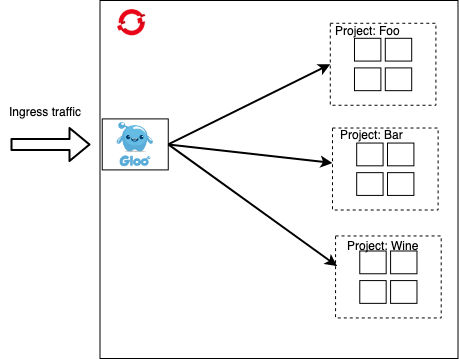
At this point this gives us basic API Gateway functionality with minimal fuss, however we want to explore ways to decentralize this deployment. At the moment, it’s still fairly centralized and shared, although much less so from a process perspective because we can use GitOps and other declarative, SCM-driven approaches to self-service the configuration of Gloo Gateway at this point. Gloo Gateway’s configuration is declarative and defined as CRDs in Kubernetes/OpenShift. If we need further isolation, we can also use proxy sharding which Gloo Gateway supports and assign certain APIs to their own gateways. This involves a slight management overhead, but allows you to separate failure domains for higher-value APIs.
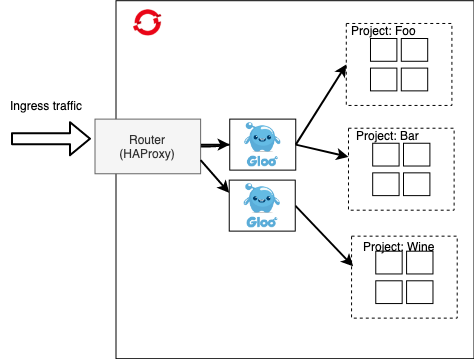
This solves some problems experienced with Legacy API Management vendors where a single API could take down the gateway for an entire set of APIs because isolation or bulkheading is not enforced.
Across multiple clusters
The previous deployment patterns can be extended out to multiple clusters. You may have multiple clusters divided by team, or service boundary, or some other construct. You may wish to abstract how your services get exposed to other parts of the organization by using an API Gateway. Gloo Gateway can play very well in this deployment. Each cluster would have its own deployment of the Gloo Gateway control plane with various proxies (see above) playing a role of ingress, sharded ingress, or even bounded context-API.
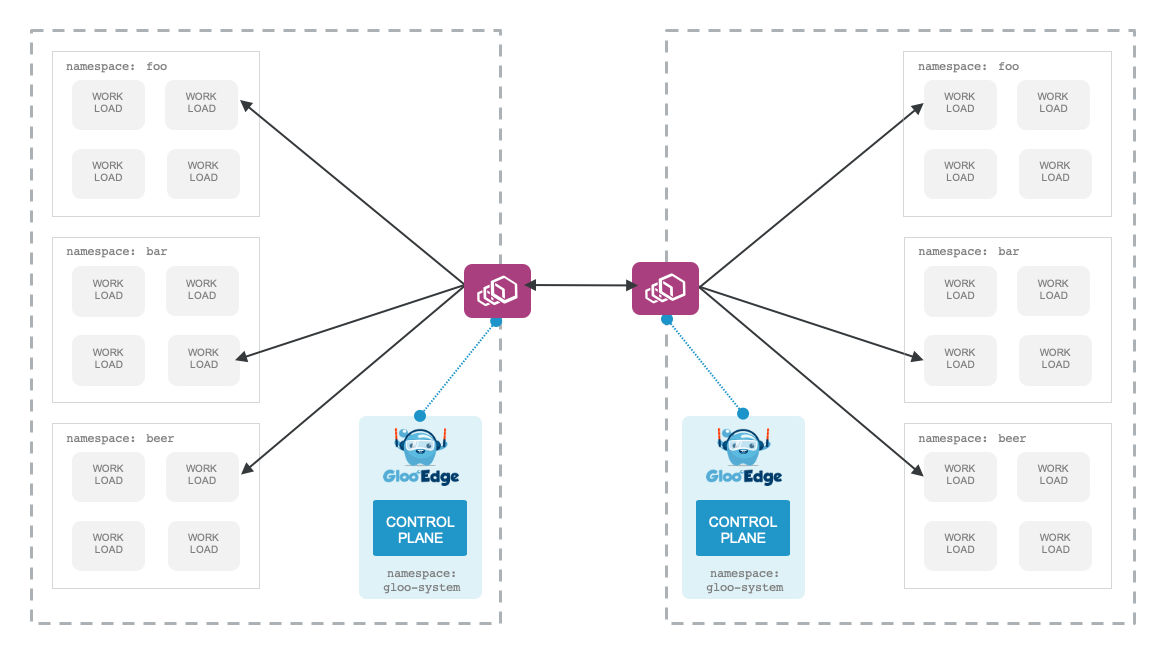
In this model, all traffic between the clusters routes between the API Gateways with appropriate security and policy enforced at these ingress/egress points.
Next Steps
Now that you have an understanding of the Gloo Gateway deployment patterns, there are number of potential next steps that we’d like to recommend.
- Getting Started: Deploy Gloo Gateway yourself.
- Deployment Options: Learn about specific implementations of Gloo Gateway with Kubernetes or HashiCorp.
- Concepts: Learn more about the core concepts behind Gloo Gateway and how they interact.
- Developer Guides: extend Gloo Gateway’s functionality for your use case through various plugins.