Release notes
Review summaries of the main changes in the Gloo 2.6 release.
Make sure that you review the breaking changes 🔥 that were introduced in this release and the impact that they have on your current environment.
Introduction
The release notes include important installation changes and known issues. They also highlight ways that you can take advantage of new features or enhancements to improve your product usage.
For more information, see the following related resources:
- Changelog: A full list of changes, including the ability to compare previous patch and minor versions.
- Upgrade guide: Steps to upgrade from the previous minor version to the current version.
- Version reference: Information about Solo’s version support.
🔥 Breaking changes
Review details about the following breaking changes. To review when breaking changes were released, you can use the comparison feature of the changelog. The severity is intended as a guide to help you assess how much attention to pay to this area during the upgrade, but can vary depending on your environment.
🚨 High
Review severe changes that can impact production and require manual intervention.
Automatic resource validation: A new feature that validates Gloo custom resources. This feature is enabled by default. Invalid resources do not block the upgrade. However, after the upgrade, you cannot make any changes to your invalid resources until the errors are resolved. This can block development of or updates to your existing Gloo resources.
Istio 1.21 support - JWT policy translation: Translation for authorization-related fields, such as
requiredScopesorclaimschanged. If you plan to use JWT policies with Istio 1.21, you must follow the upgrade steps to safely re-create existing EnvoyFilters. If not, routes that are protected by JWT policies might fail open.New feature gate for east-west routes in JWT policies: Use the
applyToRoutesselector in JWT policies to select east-west service mesh routes. If you previously selected east-west routes in your JWT policies, these policies were not enforced. However, after the upgrade, the policy might take effect and can lead to unexpected results.Fix for virtual destinations with multiple ports: A fix was introduced that translates virtual destinations with multiple ports into an Istio service entry with a single endpoint. This change requires existing Istio service and workload entries to be re-created during the upgrade. Old entries must be removed. If you have virtual destinations with multiple ports, you must follow a thorough upgrade procedure that involves scaling down the Gloo management server, Gloo agent, and istiod control plane.
🔔 Medium
Review changes that might have impact to production and require manual intervention, but possibly not until the next version is released.
- New Helm defaults for Solo image repositories: The default Helm values for the Solo images changed from
docker.iotogcr.io. Make sure to update any internal tooling, such as in airgapped environments.
ℹ️ Low
Review informational updates that you might want to implement but that are unlikely to materially impact production.
- Upstream Prometheus Helm chart upgrade: The Prometheus Helm chart version is upgraded to a newer version, which requires the Prometheus deploymented to be re-created. Gloo Mesh Enterprise uses a Helm pre-upgrade hooks to re-create the deployment which can cause issues in automated environments, such as Argo CD.
- Istio 1.21 support -
VERIFY_CERTIFICATE_AT_CLIENT: TheVERIFY_CERTIFICATE_AT_CLIENTfeature flag is enabled by default to automatically verify server certificates by using the OS CA certificates on the cluster node. You can configure Istio to use custom CA certificates. - Documentation for add-ons namespace: In all guides for Gloo Mesh Enterprise add-ons, such as for the portal, external auth, and rate limiting servers,
gloo-meshis now assumed as the add-on installation namespace. If you maintain a separate namespace for add-ons, be sure to adjust the sample resources as necessary.
Automatic resource validation
In Gloo Mesh Enterprise 2.6 and later and Kubernetes 1.25 and later, the fields of select Gloo CRDs contain constraints and rules to ensure that only valid configuration is admitted to your Gloo setup. This feature is enabled by default to ensure that any attempt to apply invalid configuration to your cluster is rejected. To see the constraints and rules for each field, check the API reference docs for each custom resource and look for the Configuration constraints. For more information, see the resource validation overview.
If you have invalid resources that you do not fix before you upgrade, you can still complete the upgrade to 2.6. However, after the upgrade, you cannot make any changes to your invalid resources until the errors are resolved. This can block development of or updates to your existing Gloo resources.
Before you upgrade to 2.6, complete the following steps to ensure that your 2.5 Gloo CRs are valid according to the rules that are enforced in 2.6.
Automatic admission validation is enabled by default in version 2.6 and later. If your resources contain invalid configuration, they are rejected. This can interrupt automated processes that apply CRs to your environment, such as GitOps pipelines. To disable this feature, upgrade your Gloo CRDs Helm chart to include the --set disableAdmissionValidation=true flag.
helm upgrade -i gloo-platform-crds gloo-platform/gloo-platform-crds \
--namespace=gloo-mesh \
--create-namespace \
--version=$GLOO_VERSION \
--set disableAdmissionValidation=true
Update
meshctlto the 2.6 patch version you want to upgrade to.curl -sL https://run.solo.io/meshctl/install | GLOO_MESH_VERSION=v$UPGRADE_VERSION sh -Run the following command to validate your existing resources. For more information, see the CLI command reference.
meshctl x validate resources --context $MGMT_CONTEXTCheck the Resource Errors & Warnings section of the output for any errors in your CRs. In this example output, one error is reported for the
ExtAuthPolicyresource namedworkload-00014-portal-rt-delegate-apiin thegloo-meshnamespace. Warnings are also reported forServiceandVirtualDestinationresources, but note that warnings do not prevent resources from being applied.... Resource Errors & Warnings ┌─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐ | Cluster | Kind | Ns/Name | Errors | Warnings | | --------------------------------------------------------------------------------------------------------------------------------------------- | | cluster-1 | Service | workload-00019-cluster-1/workload-00019 | 0 | 25 | | --------------------------------------------------------------------------------------------------------------------------------------------- | | cluster-1 | VirtualDestination | workload-00014-cluster-1/workload-00014-portal-cluster-1-692abccf4324f8554e3a4dc66077734 | 0 | 25 | | --------------------------------------------------------------------------------------------------------------------------------------------- | | cluster-1 | ExtAuthPolicy | gloo-mesh/workload-00014-portal-rt-delegate-api | 1 | 0 | | --------------------------------------------------------------------------------------------------------------------------------------------- | └─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘ Saved to /var/folders/b5/9rwm6sld7w3bw7q0wnnd0ym40000gn/T/validate-logs/input-resource-errors.jsonIf errors are reported:
- Check the errors by opening the generated
input-resource-errors.jsonfile, such as/var/folders/b5/9rwm6sld7w3bw7q0wnnd0ym40000gn/T/validate-logs/input-resource-errors.jsonin the example output of the previous step. - Update your resources to fix the invalid fields. To review the constraints and rules for each field, check the API reference docs for each custom resource and look for the Configuration constraints.
- Run the validation checks on your updated resource YAML files.
meshctl x validate resources <updated-resources>.yaml - Apply the updated, valid resources to your management cluster.
- Check the errors by opening the generated
After you confirm that all resources are valid and that no errors are reported, proceed to upgrade your Gloo Mesh Enterprise installation.
Istio 1.21 support
JWT policy translation:
Gloo Mesh Enterprise version 2.6 now supports Istio version 1.21. To support Istio 1.21, the translation of JWTPolicy custom resources into EnvoyFilters changed. If you currently use Gloo JWT policies in your environment that configure authorization-related fields, such as requiredScopes or claims and you plan to upgrade to Istio 1.21, you must upgrade the Gloo management server to version 2.6 first. Upgrading the management server ensures that the translation logic for JWTPolicy custom resources is updated and that the Gloo management server re-generates existing EnvoyFilters to make them compatible with Istio version 1.21.
To upgrade your Gloo Mesh Enterprise version, see the Upgrade docs.
If you do not upgrade the Gloo management server to 2.6 prior to upgrading to Istio 1.21, existing JWTPolicy custom resources cannot be translated correctly, and routes or apps that are protected by JWT policy authorization rules might fail open. Note that if you configured your ingress gateway to deny all requests by default, authentication to JWT-protected routes will fail and return a 401 HTTP response code. However, JWT-related authorization rules might fail to get enforced.
VERIFY_CERTIFICATE_AT_CLIENT enabled by default:
Additionally, note that in Istio 1.21, the VERIFY_CERTIFICATE_AT_CLIENT feature flag is set to true by default to automatically verify server certificates by using the OS CA certificates on the cluster node.
New feature gate for east-west routes in JWT policies
Now, you can use the applyToRoutes selector in JWT policies to select east-west service mesh routes.
Previously, you could only select ingress routes that were attached to a virtual gateway. The use of a virtual gateway for ingress routes required a Gloo Mesh Gateway license in addition to your Gloo Mesh Enterprise license. For a Mesh-only scenario, you previously had to use the applyToDestinations selector. This meant that the same JWT policy applied to the destinations no matter how traffic reached them.
Now, you can use applyToRoutes for east-west routes. This way, you have more flexibility in how a destination is protected. For example, you might have several external and internal routes that go to the same backing destination. To secure these routes with different JWT policies, you can use applyToRoutes instead of applyToDestinations.
Depending on your existing JWT policy setup, this new feature can cause unexpected results. For example, you might have east-west routes that are selected by a JWT policy. However, because JWT policies did not work for east-west routes in version 2.5 and earlier, the JWT policy did not take effect. Your workloads within the service mesh could communicate to each other without including valid JWTs in the request. Now with this feature enabled, those same requests require valid JWTs. As such, you might notice service mesh traffic stop working until you update your JWT policies or east-west routes in your route tables. Continue with the following steps.
Verify if you are affected by this change in 2.6:
- Check your existing JWT policies that use
applyToRoutesselectors and note the routes that they apply to. - Check your existing route tables with the routes that you previously noted.
- Determine whether JWT policies apply to east-west service mesh routes.
- If a route table includes a workload selector, or if a route table omits both the virtual gateway and workload selector fields: The JWT policies apply to the east-west service mesh routes. This might conflict with other JWT policies that already select the backing destinations of these routes.
- If the route tables do not include a workload selector (except in the case that the route table also does not include a virtual gateway): The JWT policies do not apply to the east-west service mesh routes.
- Decide how to address the potential impact of updating the behavior of the JWT policy
applyToRoutesselector.- To prevent JWT policies from applying to east-west service mesh routes, choose from the following options:
- Update your configuration. For example, you might use a different label to select routes. Or, you might make separate route tables with separate route labels for your ingress routes vs. east-west routes.
- Disable the feature gate by upgrading your Gloo Helm release with the
featureGates.EnableJWTPolicyEastWestRoutevalue set tofalse.
- If you want to leverage this new feature and you have existing JWT policies that are applied to east-west routes, follow the recommended upgrade procedure.
- To prevent JWT policies from applying to east-west service mesh routes, choose from the following options:
Recommended upgrade procedure:
- Enable
featureGates.EnableJWTPolicyEastWestRoutefeature gate in a test environment in 2.5 by carefully following the 2.5 upgrade procedure. You can also reach out to your account representative and provide Solo with an input snapshot from your environment. Solo engineers can then verify the impact of this change for your environment. - After the impact of this change is known and verified, upgrade your environment to the latest 2.5 patch version with the
featureGates.EnableJWTPolicyEastWestRouteset totrue. Use the steps in the 2.5 upgrade guide to perform this upgrade. - Then, follow the 2.6 upgrade guide to upgrade your environment from 2.5 to 2.6. Note that in version 2.6 and later, the feature gate is enabled by default.
For more information, see the following resources:
Route and destination selectors for JWT policies conceptual overview
Feature gates reference docs
Fix for virtual destinations with multiple ports
In previous versions, virtual destinations that specified multiple ports were translated into Istio service entries with valid and invalid endpoints. In cross-cluster routing scenarios, the east-west gateway forwards traffic between multiple clusters. To fulfill the routing request, the east-west gateway uses the endpoint specification on the Istio service entry. Because multiple endpoints are specified, the east-west gateway load balances requests between these endpoints. When a valid endpoint is hit, a 200 HTTP response code is returned. However, if an invalid endpoint is hit, an HTTP error response code is returned.
To fix this issue, the Istio service entry translation logic changed. Virtual destinations with multiple ports are now translated into an Istio service entry with one endpoint that has multiple ports, such as in this example:
endpoints:
- address: 172.18.0.6
labels:
app: ext-auth-service
security.istio.io/tlsMode: istio
ports:
grpc-8083: 32733
tcp-9091: 32733
tcp-8082: 32733
Changing the ports in the service entries also changes the ports in the corresponding workload entry. Because of that, the workload entry hash that is part of the name must be re-calculated, which changes the name of the workload entry. If you used virtual destinations with multiple ports, the corresponding service and workload entries must be re-created during the upgrade to 2.6. This process requires a careful upgrade procedure to ensure that new entries are created and old entries are correctly removed. Make sure that you thoroughly follow the steps in the upgrade guide.
Verify if you are impacted by this change in 2.6:
Check the virtual destinations in your environment and note the ones that specify multiple ports. The following example shows how a virtual destination with multiple ports might look like.
apiVersion: networking.gloo.solo.io/v2
kind: VirtualDestination
metadata:
name: server-vd
namespace: helloworld
spec:
hosts:
- helloworld.vd
ports:
- number: 9000
protocol: TCP
targetPort:
number: 9000
- number: 5000
protocol: HTTP
targetPort:
number: 5000
services:
- labels:
app: helloworld
namespace: helloworld
Recommended upgrade procedure:
- If your virtual destinations specify only one port, you are not affected by this change. You can continue with the steps in the upgrade guide to perform the upgrade to 2.6.
- If you have virtual destinations with multiple ports, you must follow a careful upgrade procedure that involves scaling down the Gloo management server, Gloo agent, and istiod control plane. Use the steps in the 2.5 upgrade guide as a general guidance for how to perform the upgrade to 2.6.
New Helm defaults for Solo image repositories
The default Helm values for the Solo images changed from docker.io to gcr.io. For example, the Redis image changed from docker.io/redis:7.2.4-alpine to gcr.io/gloo-mesh/redis:7.2.4-alpine. If you internal tooling is set up to pull the images from docker.io, such as in air-gapped environments, you must update that tooling to pull the images from the Google Cloud Registry repository.
For an overview of the images that are used in an air-gapped environment, see the Install in air-gapped environments docs in the Gloo Mesh Enterprise documentation.
Upstream Prometheus upgrade
Gloo Mesh Enterprise includes a built-in Prometheus server to help monitor the health of your Gloo components. This release of Gloo upgrades the Prometheus community Helm chart from version 19.7.2 to 25.11.0. As part of this upgrade, upstream Prometheus changed the selector labels for the deployment, which requires recreating the deployment. To help with this process, the Gloo Helm chart includes a pre-upgrade hook that automatically recreates the Prometheus deployment during a Helm upgrade. This breaking change impacts upgrades from previous versions to version 2.4.10, 2.5.1, or 2.6.0 and later.
If you do not want the redeployment to happen automatically, you can disable this process by setting the prometheus.skipAutoMigration Helm value to true. For example, you might use Argo CD, which converts Helm pre-upgrade hooks to Argo PreSync hooks and causes issues. To ensure that the Prometheus server is deployed with the right version, follow these steps:
- Confirm that you have an existing deployment of Prometheus at the old Helm chart version of
chart: prometheus-19.7.2.kubectl get deploy -n gloo-mesh prometheus-server -o yaml | grep chart - Delete the Prometheus deployment. Note that while Prometheus is deleted, you cannot observe Gloo performance metrics.
kubectl delete deploy -n gloo-mesh prometheus-server - In your Helm values file, set the
prometheus.skipAutoMigrationfield totrue. - Continue with the Helm upgrade of Gloo Mesh Enterprise. The upgrade recreates the Prometheus server deployment at the new version.
⚒️ Installation changes
In addition to comparing differences across versions in the changelog, review the following installation changes from the previous minor version to version 2.6.
Safe mode enabled by default
Starting in version 2.6.0, safe mode is enabled on the Gloo management server by default to ensure that the server translates input snapshots only if all input snapshots are present in Redis or its local memory. This way, translation only occurs based on a complete translation context that includes all workload clusters.
Enabling safe mode resolves a race condition that was identified in version 2.5.3, 2.4.11, and earlier that could be triggered during simultaneous restarts of the management plane and Redis, including an upgrade to a newer Gloo Mesh Enterprise version. If hit, this failure mode could lead to partial translations on the Gloo management server which could result in Istio resources being temporarily deleted from the output snapshots that are sent to the Gloo agents.
To learn more about safe mode, see Safe mode.
Enabling safe mode requires the Gloo management server to be scaled down to 0 replicas. Make sure to follow the upgrade guide to safely upgrade your Gloo Mesh Enterprise installation.
New default values for Gloo UI auth sessions
Some of the default Helm values changed for configuring the Gloo UI auth session storage:
glooUi.auth.oidc.session.backend: The default value changed from""(empty) tocookieto ensure auth sessions are stored in browser cookies by default.glooUi.auth.oidc.session.redis.host: The default value changed from""(empty) togloo-mesh-redis.gloo-mesh:6379to ensure a valid Redis host is set whenglooUi.auth.oidc.session.backendis changed toredis.
To learn how to set up Gloo UI auth session storage, see Store UI sessions.
New container settings for Redis
In 2.6, the default container settings for the built-in Redis changed. To apply these settings, Redis must be restarted during the upgrade. Make sure that safe mode is enabled before you proceed with the upgrade so that translation of input snapshots halts until the input snapshots of all connected Gloo agents are re-populated in Redis. In 2.6.0, safe mode is enabled by default.
To learn more about safe mode, see Safe mode.
Redis installation for snapshots, insights, external auth service, and rate limiter
Previously, you configured the details for the backing Redis instance for different Gloo Mesh Enterprise components in the Helm chart section for each component. When components had to share Redis instances, this approach could lead to misconfiguration. For example, the Gloo external auth service and portal server must share the same configuration details to use the same Redis instance, but these Redis details were configured separately.
Now, you can configure the details for the backing Redis instance consistently across components by using the new redisStore section of the Helm chart. The redisStore section also organizes Redis into four main use cases, which you can configure to use separate Redis instances. All the components that read or write data for this particular use case automatically get the same Redis details set up for them. This way, you can consistently configure Redis.
Example of the new configuration
Compare the following redisStore configuration block to how the configuration was done in previous versions. The example sets up built-in backing Redis instances for each use case: snapshot, insights, extAuthService (which is also used by the developer portal), and rateLimiter.
Upgrade impact
The previous way of configuring Redis is still supported, so you do not have to update your configuration right away. However, you might want to update to redisStore for simplicity, as well as to use the new use case-driven approach that lets you configure Redis for snapshot, insights, extAuthService, and rateLimiter.
For more information, see the updated Redis documentation.
🌟 New features
Review the following new features that are introduced in version 2.6 and that you can enable in your environment.
Istio 1.21 and 1.22 support
Starting in version 2.6.0, you can now use Istio 1.21 and 1.22. Note that you must upgrade the Gloo management server to version 2.6 first before you start upgrading your Istio version. To find the image reposititories for the Solo distribution of Istio, see the Istio images built by Solo support article. Istio versions 1.16 and 1.17 are no longer supported in 2.6.
If you plan to use Istio 1.21, make sure to review the Breaking changes when using Istio 1.21.
For more information about supported Istio versions, see the Supported Solo distributions of Istio.
Kubernetes 1.29 and 1.30 support
Starting in version 2.6.0, Gloo Mesh Enterprise can now run on Kubernetes 1.29 and 1.30. Kubernetes version 1.22 and 1.23 are no longer supported. For more information about supported Kubernetes and Istio versions, see the version support matrix.
I/O threads for Redis
A new Helm value redis.deployment.ioThreads was introduced to specify the number of I/O threads to use for the built-in Redis instance. Redis is mostly single threaded, however some operations, such as UNLINK or slow I/O accesses can be performed on side threads. Increasing the number of side threads can help improve and maximize the performance of Redis as these operations can run in parallel.
The default and minimum valid value for this setting is 1. If you plan to increase the number of I/O side threads, make sure that you also change the CPU requests and CPU limits for the Redis pod. Set the CPU requests and limits to the same number that you use for the I/O side threads plus 1. That way, you can ensure that each side thread has an available CPU core, and that an additional CPU core is left for the main Redis thread. For example, if you want to set I/O threads to 2, make sure to add 3 CPU cores to the resource requests and limits for the Redis pod. You can find further recommendations regarding I/O threads in this Redis configuration example.
If you set I/O threads, the Redis pod must be restarted during the upgrade so that the changes can be applied. During the restart, the input snapshots from all connected Gloo agents are removed from the Redis cache. If you also update settings in the Gloo management server that require the management server pod to restart, the management server’s local memory is cleared and all Gloo agents are disconnected. Although the Gloo agents attempt to reconnect to send their input snapshots and re-populate the Redis cache, some agents might take longer to connect or fail to connect at all. To ensure that the Gloo management server halts translation until the input snapshots of all workload cluster agents are present in Redis, it is recommended to enable safe mode on the management server alongside updating the I/O threads for the Redis pod. For more information, see Safe mode. Note that in version 2.6.0 and later, safe mode is enabled by default.
To update I/O side threads in Redis as part of your Gloo Mesh Enterprise upgrade:
Scale down the number of Gloo management server pods to 0.
kubectl scale deployment gloo-mesh-mgmt-server --replicas=0 -n gloo-meshUpgrade Gloo Mesh Enterprise and use the following settings in your Helm values file for the management server. Make sure to also increase the number of CPU cores to one core per thread, and add an additional CPU core for the main Redis thread. The following example also enables safe mode on the Gloo management server to ensure translation is done with the complete context of all workload clusters.
glooMgmtServer: safeMode: true redis: deployment: ioThreads: 2 resources: requests: cpu: 3 limits: cpu: 3Scale the Gloo management server back up to the number of desired replicas. The following example uses 1 replica.
kubectl scale deployment gloo-mesh-mgmt-server --replicas=1 -n gloo-mesh
Gloo insights and improved UI
In version 2.6.0 and later, Gloo Mesh Enterprise comes with an insights engine that automatically analyzes your Istio setups for health issues. Then, Gloo shares these issues along with recommendations to harden your Istio setups. The insights give you a checklist to address issues that might otherwise be hard to detect across your environment. Note that in large-scale environments, allotting additional resources to the engine and analyzer components is recommended. For an overview of available insights and more information, see Insights.
To enable insights generation, you must include the following settings when you upgrade your Helm installations:
--set glooInsightsEngine.enabled=truein your management cluster--set glooAnalyzer.enabled=truein each workload cluster
Consider deploying a dedicated Redis instance to store insights data, which is recommended to separate observability data from the snapshot data that the Redis instance for your management server stores. You can enable a Gloo-managed Redis instance for the insights engine by including the --set redisStore.insights.deployment.enabled=true setting in your management cluster when you upgrade your Gloo Mesh Enterprise installation. For a more secure setup, you can instead bring your own Redis instance, and use the --set redisStore.insights.client.address=<external_redis_address> setting to point to the external address of your Redis instance. For more information, see Backing databases.
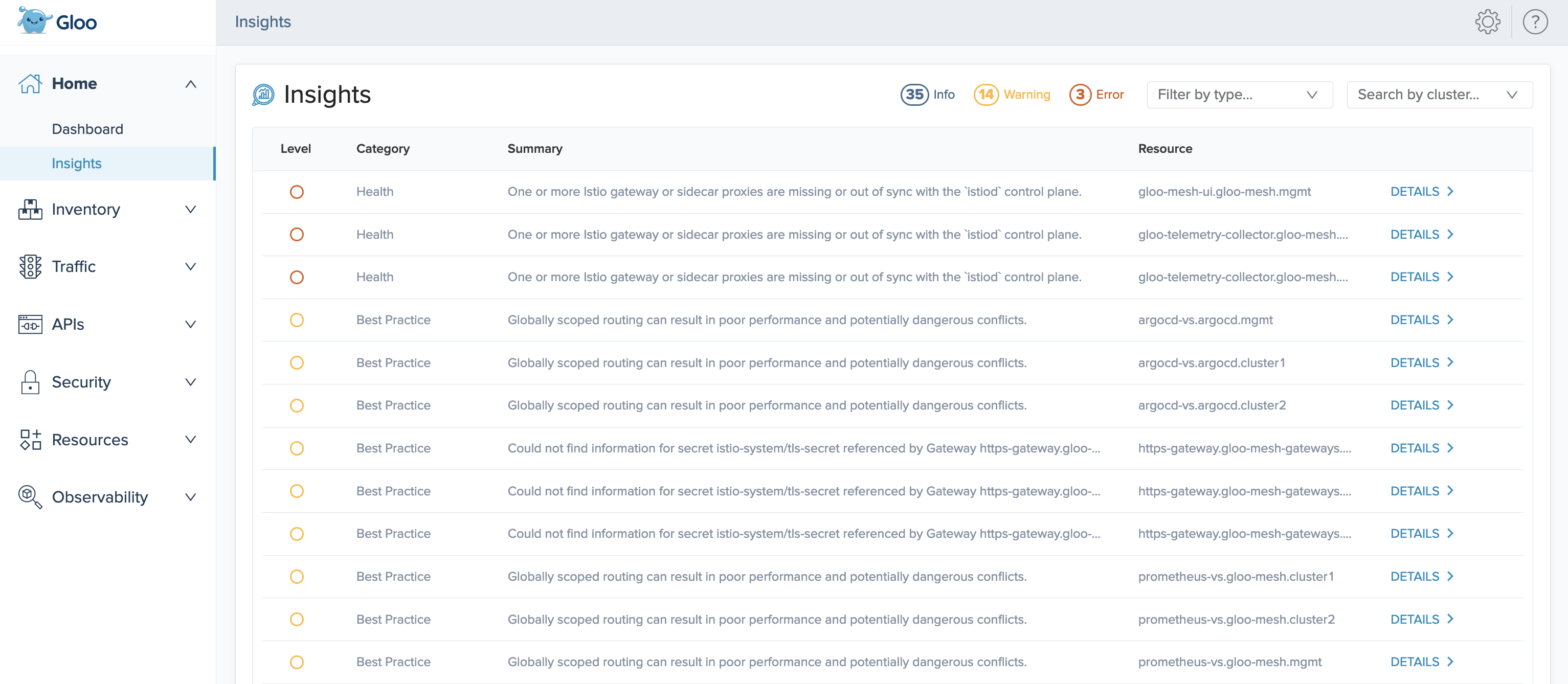
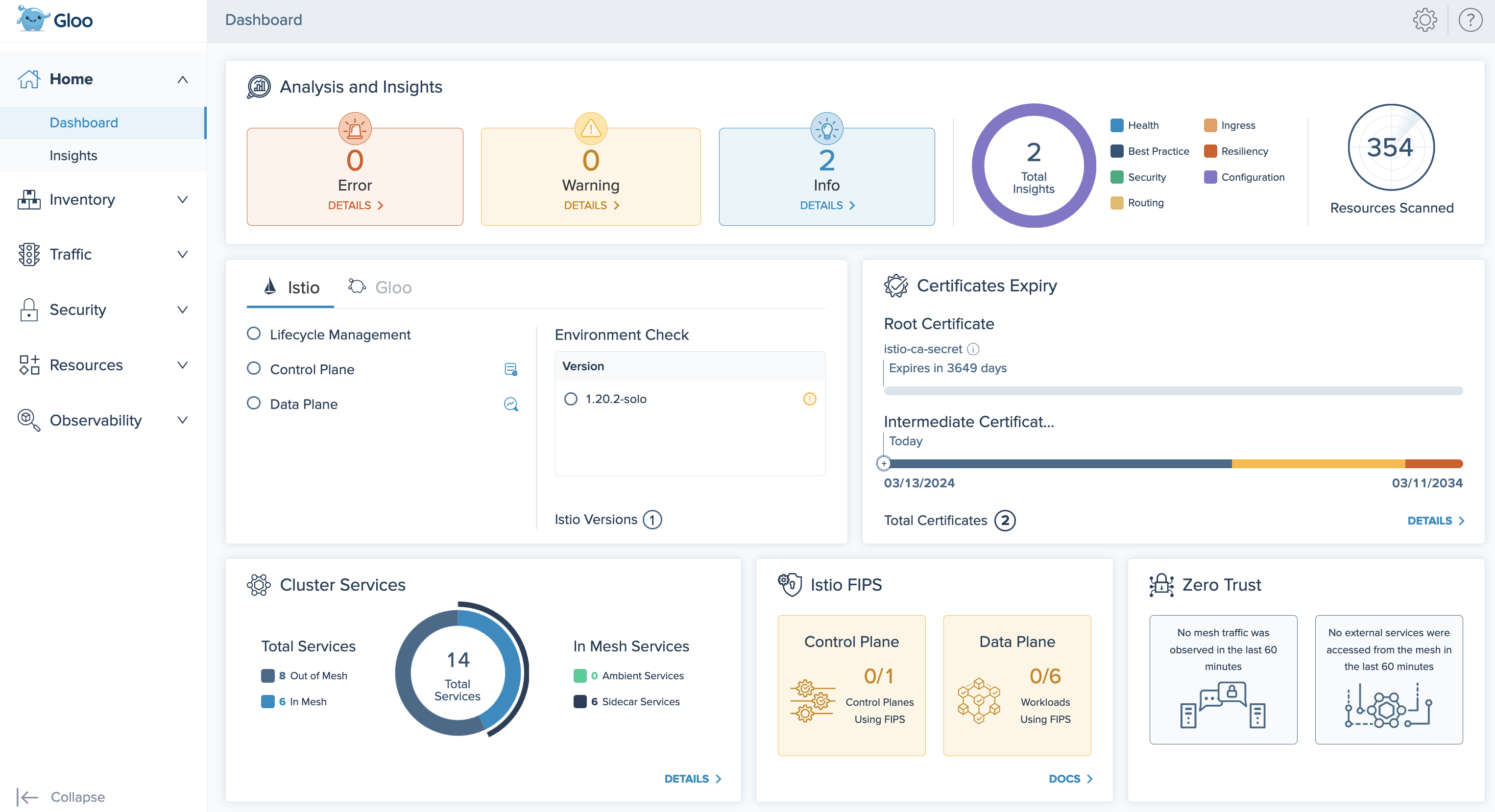
Additionally, when you enable insights in your Gloo Mesh Enterprise installation, the Gloo UI is updated with an improved Dashboard to help you quickly review the health and status of your environment. To review the new features, see Explore the new UI with insights.
Persistence mode for built-in Redis
To back up data for the Gloo Mesh Enterprise control plane components like the management server, you can use a Solo-provided built-in Redis instance that is installed in the cluster. By default, this built-in Redis instance does not persist data, which gets lost during pod restarts. Now, you can also configure the built-in Redis to use persistent storage. This way, data persists across Redis restarts, such as after an upgrade. By persisting the data, you can reduce delays in the relay process that otherwise would happen after a restart. For more information, see Persistent storage.
New feature gate for VirtualDestinationWorkspacePolicyOverride
Previous, virtual destinations that were imported from a source workspace to a target workspace kept the client-side attached policies from the source workspace. Also, when a virtual destination was backed by services on the same host that had different policies attached, the applied policy could be unpredictable.
Now, when you enable the VirtualDestinationWorkspacePolicyOverride feature gate, these policy behaviors are changed to improve consistency and client-side control.
Imported virtual destinations still keep their client-side attached policies from the source workspace. However, you as the target workspace owner can apply your own client-side policies to override the policies from the source workspace. This way, each team can set its own policies for the virtual destination within their own workspace, but share the virtual destination configuration across teams.
Additionally, underlying services behind a virtual destination now can use subset routing. After enabling the feature gate, this feature automatically works in scenarios where you have overriding policies that apply to a virtual destination that is imported across workspaces. This way, services in different workspaces that use the same virtual destination host can have distinct client-side policies where applicable, such as for failover traffic.
Enabling the VirtualDestinationWorkspacePolicyOverride feature gate entails a period of dropped traffic for the impacted virtual destinations. Also, you cannot disable this feature after enabling. Review the following steps before you enable the feature gate.
- Determine whether you need to enable the
VirtualDestinationWorkspacePolicyOverridefeature gate. With the feature gate enabled, you can override client-side policies when importing virtual destinations from a source workspace in to a target workspace. This way, you can apply your own client-side policies in the importing target workspace. Client-side policies include the following. For more information, see the Import and export policies conceptual overview.- ActiveHealthCheckPolicy
- AdaptiveRequestConcurrencyPolicy
- ClientTLSPolicy
- ConnectionPolicy for TCP
- FailoverPolicy
- LoadBalancerPolicy
- OutlierDetectionPolicy
- Assess the impact to your setup if you enable the feature gate.
- Any virtual destinations that currently have client-side policies experience dropped traffic until all the configuration changes propagate across clusters.
- Configuration changes include the underlying Istio resources that are created for the policies. In particular, previously a single Istio DestinationRule per policy was created and used by the importing namespaces. Now, an Istio DestinationRule is created per namespace, increasing the number of underlying resources that are propagated.
- After the upgrade, the underlying EnvoyFilters use subset routing, which means that they have entries per client, inside of a single entry per shared virtual destination host.
- Continue with the upgrade by including the
featureGates.VirtualDestinationWorkspacePolicyOverride=truesetting. For more information, see the Feature gates reference docs.
🔄 Feature changes
Review the following changes that might impact how you use certain features in your Gloo environment.
Improved error logging
The Gloo management server translates your Gloo custom resources into many underlying Istio resources. When the management server cannot translate a resource, it returns debug logs that vary in severity from errors to warnings or info.
In this release, the management server logs are improved in the following ways:
- All translation errors are now logged at the debug level. This way, the management server logs are not cluttered by errors that do not impact the management server’s health.
- Fixed a bug that caused many duplicate error logs. Now, you have fewer logs to sift through.
For example, you might have a service that does not select any existing workloads. This scenario might be intentional, such as if you use a CI/CD tool like ArgoCD to deploy your environment in phases. Translation does not complete until you update the service’s selector or create the workload. Previously, the translation error would show up many times in the management server logs, even though the situation is intentional and the management server is healthy and can translate other objects. Now, the translation error is logged less verbosely at the debug level.
You can still review translation errors in the following ways:
- Translation errors and warnings are shown in the statuses of Gloo custom resources. For example, if a policy fails to apply to a route, you can review the warning in the policy and the route table statuses.
- In the management server, enable debug logging by enabling the
--verbose=truesetting. Example command:kubectl patch deploy -n gloo-mesh gloo-mesh-mgmt-server --type "json" -p '[{"op":"add","path":"/spec/template/spec/containers/0/args/-","value":"--verbose=true"}]'
Improved external service routing
Now, you can create multiple external services that share the same host but have different ports or wildcard subdomains. For example, you might have different teams own different subdomains of an external service. Or, several third-party services might be exposed on different ports of the same host. Previously, creating multiple external services with a conflicting wildcard host or a different port on the same host was not supported. For more information, see Route to external services.
Istio resources not generated on non-mesh clusters
Added a fix that now prevents Istio resources from being written to the management cluster when the management cluster is not registered as a workload cluster at the same time. Previously, if you had an Istio installation in your management cluster that was not managed by Gloo Mesh Enterprise and a Gloo agent was deployed to that cluster at the same time, the agent discovered these Istio resources and included them in the snapshot that was sent to the management server. The agent also wrote Istio resources to that cluster, which might have inteferred with existing Istio resources in that cluster.
Previously generated resources are not automatically removed during the upgrade. You must manually clean up these resources in the management cluster. You can use the following script to remove these resources.
#!/bin/bash
namespace=$1
if [ -z "$namespace" ]; then
echo "Usage: cleanup.sh <namespace>"
exit 1
fi
kubectl delete authorizationpolicies.security.istio.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete certificaterequests.internal.gloo.solo.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete clusteristioinstallations.internal.gloo.solo.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete destinationrules.networking.istio.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete discoveredcnis.internal.gloo.solo.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete discoveredgateways.internal.gloo.solo.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete envoyfilters.networking.istio.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete gateways.networking.istio.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete issuedcertificates.internal.gloo.solo.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete istiooperators.install.istio.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete meshes.internal.gloo.solo.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete peerauthentications.security.istio.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete podbouncedirectives.internal.gloo.solo.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete portalconfigs.internal.gloo.solo.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete proxyconfigs.networking.istio.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete requestauthentications.security.istio.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete serviceentries.networking.istio.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete sidecars.networking.istio.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete spireregistrationentries.internal.gloo.solo.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete telemetries.telemetry.istio.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete virtualservices.networking.istio.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete wasmplugins.extensions.istio.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete workloadentries.networking.istio.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete workloadgroups.networking.istio.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
kubectl delete xdsconfigs.internal.gloo.solo.io -n $namespace -l "reconciler.mesh.gloo.solo.io/name=translator"
🚧 Known issues
The Solo team fixes bugs, delivers new features, and makes changes on a regular basis as described in the changelog. Some issues, however, might impact many users for common use cases. These known issues are as follows:
Cluster names: Do not use underscores (
_) in the names of your clusters or in thekubeconfigcontext for your clusters.OTel pipeline: FIPS-compliant builds are not currently supported for the OTel collector agent image.
Istio:
- Due to a lack of support for the Istio CNI and iptables for the Istio proxy, you cannot run Istio (and therefore Gloo Mesh Enterprise) on AWS Fargate. For more information, see the Amazon EKS issue.
- Istio 1.22 is supported only as patch version
1.22.1-patch0and later. Do not use patch versions 1.22.0 and 1.22.1, which contain bugs that impact several Gloo Mesh Enterprise routing features that rely on virtual destinations. Additionally, in Istio 1.22, theISTIO_DELTA_XDSenvironment variable must be set tofalse. For more information, see this upstream Istio issue. - If you plan to upgrade to Istio 1.21, you must upgrade the Gloo management server to version 2.6 first. For more information, see the 2.6 release notes.
- Istio 1.20 is supported only as patch version
1.20.1-patch1and later. Do not use patch versions 1.20.0 and 1.20.1, which contain bugs that impact several Gloo Mesh Enterprise features that rely on Istio ServiceEntries.
- If you have multiple external services that use the same host and plan to use Istio 1.20, 1.21, or 1.22, you must use patch versions 1.20.7, 1.21.3, or 1.22.1-patch0 or later to ensure that the Istio service entry that is created for those external services is correct.
- The
WasmDeploymentPolicyGloo CR is currently unsupported in Istio versions 1.18 and later.