Transformations
One of the core features of any API Gateway is the ability to transform the traffic that it manages. To really enable the decoupling of your services, the API Gateway should be able to mutate requests before forwarding them to your upstream services and do the same with the resulting responses before they reach the downstream clients. Gloo Edge delivers on this promise by providing you with a powerful transformation API.
To review where transformations happen as Gloo Edge filters traffic, see Traffic processing.
Defining a transformation
Transformations are defined by adding the transformations attribute to your Virtual Services. You can define this attribute on three different Virtual Service sub-resources:
- VirtualHosts
- Routes
- WeightedDestinations
The configuration format is the same in all three cases and must be specified under the relevant options attribute. For example, to configure transformations for all traffic matching a Virtual Host, you need to add the following attribute to your Virtual Host definition:
# This snippet has been abridged for brevity
virtualHost:
options:
stagedTransformations:
regular:
requestTransforms:
- requestTransformation:
transformationTemplate:
headers:
foo:
text: 'bar'Inheritance rules
By default, a transformation defined on a Virtual Service attribute is inherited by all the child attributes:
- transformations defined on
VirtualHostsare inherited byRoutes andWeightedDestinations. - transformations defined on
Routes are inherited byWeightedDestinations.
If a child attribute defines its own transformation, it overrides the configuration on its parent.
However, if inheritTransformation is set to true on the stagedTransformations for a Route, it can inherit transformations
from its parent as illustrated below.
Let’s define the virtualHost and its child route is defined as follows:
# This snippet has been abridged for brevity, and only includes transformation-relevant config
virtualHost:
options:
stagedTransformations:
regular:
requestTransforms:
- matcher:
- prefix: '/parent'
requestTransformation:
transformationTemplate:
headers:
foo:
text: 'bar'
routes:
- options:
stagedTransformations:
inheritTransformation: true
regular:
requestTransforms:
- matchers:
- prefix: '/child'
requestTransformation:
transformationTemplate:
headers:
foo:
text: 'baz'Because inheritTransformation is set to true on the child route, the parent virtualHost transformation config is merged into the child. The child route’s transformations look like the following.
# This snippet has been abridged for brevity, and only includes transformation-relevant config
routes:
- options:
stagedTransformations:
inheritTransformation: true
regular:
requestTransforms:
- matchers:
- prefix: '/child'
requestTransformation:
transformationTemplate:
headers:
foo:
text: 'baz'
- matchers:
- prefix: '/parent'
requestTransformation:
transformationTemplate:
headers:
foo:
text: 'bar'As stated above, the route’s configuration overrides its parent’s, but now it also inherits the parent’s transformations. So in this case,
routes matching /parent are also transformed. If inheritTransformation were set to false, the matching /parent routes would not be transformed.
Note that only the first matched transformation runs, so if both the child and the parent had the same matchers, the child’s transformation would run.
Configuration format
Learn more about the properties that you can set in the stagedTransformations object
section of your YAML file.
The following YAML file shows a sample structure for how to configure request and response transformations in the stagedTransformations section:
stagedTransformations:
early:
# early transformations
regular:
requestTransforms:
- matcher:
prefix : '/'
clearRouteCache: bool
requestTransformation: {}
responseTransformation: {}
responseTransforms: {}
inheritTransformations: bool
The early and regular attributes are used to specify when in the envoy filter chain the transformations run. For request transformations, early transformations are applied before regular transformations as shown in the following diagram. For response transformations, this order is reversed, and regular transformations are applied before early transformations. To learn more about the order in which envoy filters are applied, see HTTP filter chain processing in the envoy documentation.
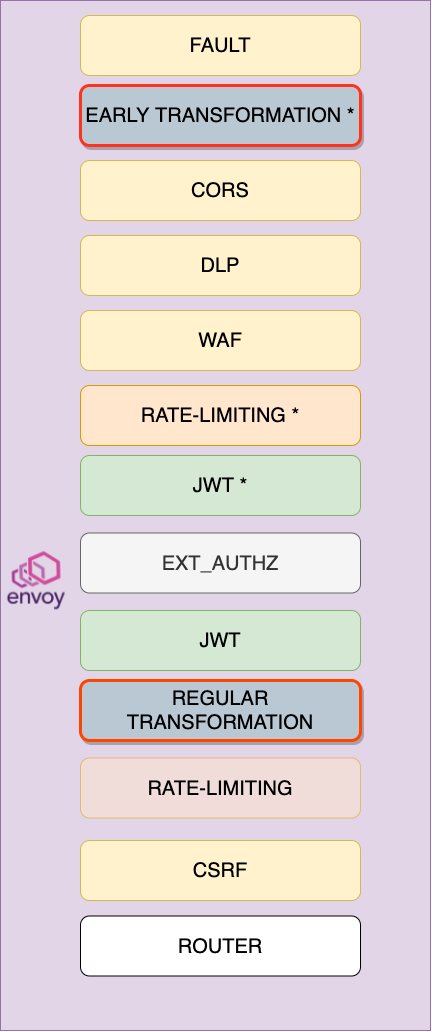
The requestTransforms attribute specifies a list of transformations that are applied when a matching request is found. The first transformation that specifies a matcher that matches the request attributes is applied.
The responseTransforms attribute specifies a list of transformations that are applied when a matching response is found. A transformation is applied only if no transformation in requestTransforms matched the request.
The clearRouteCache attribute is a boolean value that determines whether the route cache should be cleared if the request transformation was applied. If the transformation modifies the headers in a way that affects routing, this attribute must be set to true. The default value is false.
The requestTransformation and responseTransformation attributes have the same format
and specify transformations that are applied to requests and responses respectively. The format can be one of the following:
headerBodyTransform: This type of transformation makes all the headers available in the body and returns a JSON body that consists of two attributes:headers, containing the headers, andbody, containing the original body.- If
addRequestMetadatais true,queryString,queryStringParameters,multiValueQueryStringParameters,httpMethod,path, andmultiValueHeaderswill additionally be present in the body.
- If
transformationTemplate: This type of transformation allows you to define transformation templates. This is the more powerful and flexible type of transformation. For more information, see Transformation templates.xsltTransformation: This type of transformation allows you to use the XSLT transformation language to describe your transformation. For more information, see XSLT Transformation.
The inheritTransformation attribute allows child routes to inherit transformations from their parent RouteTables and/or VirtualHosts. For more information, see Inheritance rules.
Transformation templates
Templates
are the core of Gloo Edge’s transformation API. They allow you to mutate the headers and bodies of requests and responses based on the properties of the headers and bodies themselves. The following snippet illustrates the structure of the transformationTemplate object:
transformationTemplate:
parseBodyBehavior: {}
ignoreErrorOnParse: bool
extractors: {}
headers: {}
# Only one of body, passthrough, and mergeExtractorsToBody can be specified
body: {}
passthrough: {}
mergeExtractorsToBody: {}
dynamicMetadataValues: []
advancedTemplates: bool
escapeCharacters: bool
The body, passthrough, and mergeExtractorsToBody attributes define three different ways of handling the body of the request/response. Please note that only one of them may be set, otherwise Gloo Edge will reject the transformationTemplate.
Let’s go ahead and describe each one of these attributes in detail.
Body Parsing Behavior
By default, transformationTemplate parses the request/response body as JSON, depending on whether you configure a requestTransformation or responseTransformation. If Gloo Edge fails to parse the request/response body as JSON, it returns a 400 Bad Request error.
If you want to skip this behavior, you can:
- Set the
parseBodyBehaviorattribute toDontParse. Edge buffers the body as plain text and does not parse it. - Set the
ignoreErrorOnParseattribute totrue. Edge parses the body as JSON, but does not return an error if the body is not valid JSON. - Enable
passthrough. Edge does not parse or buffer the body.
parseBodyBehavior
This attribute determines how the request/response body will be parsed and can have one of two values:
ParseAsJson: Gloo Edge will attempt to parse the body as a JSON structure. This is the default behavior.DontParse: the body will be treated as plain text.
The important part to know about the DontParse setting is that the body will be buffered and available, but will not be parsed. If you’re looking to skip any body buffering completely, see the section on passthrough: {}
As we will see later, some of the templating features won’t be available when treating the body as plain text.
ignoreErrorOnParse
By default, Gloo Edge will attempt to parse the body as JSON, unless you have DontParse set as the parseBodyBehavior. If ignoreErrorOnParse is set to true, Envoy will not throw an exception in case the body parsing fails. Defaults to false.
Implicit in this setting is that the body will be buffered and available. If you’re looking to skip any body buffering completely, see the section on passthrough: {}
extractors
Use this attribute to extract information from a request or response. It consists of a set of mappings from a string to an extraction:
- the
extractiondefines which information will be extracted - the string key will provide the extractor with a name it can be referred by.
An extraction must have one of two sources:
header: extract information from a header with the given name.extractors: myExtractor: header: 'foo' regex: '.*'body: extract information from the body. This attribute takes an empty value (as there is always only one body).extractors: myExtractor: body: {} regex: '.*'
The body extraction source has been introduced with Gloo Edge, release 0.20.12, and Gloo Edge Enterprise, release 0.20.7. If you are using an earlier version, it will not work.
Extracting the body is generally not useful when Gloo Edge has already parsed it as JSON, the default behavior. The parsed body data can be directly referenced using standard JSON syntax. The body extractor treats the body as plaintext, and is interpreted using a regular expression as noted below. This can be useful for body data that cannot be parsed as JSON.
An extraction must also define which information is to be extracted from the source. This can be done by providing a regular expression via the regex attribute. The regular expression will be applied to the body or to the value of relevant header and must match the entire source. If your regular expression uses capturing groups, you can select the group match you want to use via the subgroup attribute.
The regex attribute is required when specifying an extraction. Even if a regex attribute is not required to capture a subset of the source information, you must still specify a catch-all pattern like regex: '.*'. If no regex is specified, the extractor will silently fail.
The regex must match the entire source even if you are looking to extract a subset of the source information in a capturing group. If the regex doesn’t match the entire input, the regex will silently fail.
As an example, to define an extraction named foo which will contain the value of the foo query parameter you can apply the following configuration:
extractors:
# This is the name of the extraction
foo:
# The :path pseudo-header contains the URI
header: ':path'
# Use a nested capturing group to extract the query param
regex: '(.*foo=([^&]*).*)'
# Select the second group match
subgroup: 2
Another example shows how to extract a value from the body using a regex. If the body is:
Here is a body containing the identification number of the object.
id: 4423
and we want to extract the id number, we can define an extractor:
extractors:
# This is the name of the extraction
bodyIdExtractor:
# This empty struct must be included to extract from the body
body: {}
# The regex must match the ENTIRE body, else the extraction will not work
# The [\s\S]* allows us to match any character, making the regex match the entire source.
regex: '[\s\S]*id: ([0-9]{4})[\s\S]*'
# Select the first subgroup match ([0-9]{4}) since we only want the id number
subgroup: 1
The result will be the bodyIdExtractor having value 4423.
Extracted values can be used in two ways:
- You can reference extractors by their name in template strings.
- If
advancedTemplatesis set tofalse, format the string such as{{ my-extractor }}. - If
advancedTemplatesis set totrue, format the string such as{{ extraction(my-extractor) }}.
- If
- You can use them in conjunction with the
mergeExtractorsToBodybody transformation type to merge them into the body.
Extractor Modes
Starting with Gloo Edge 1.15, extractors support multiple different modes of operation. These modes enable more powerful and flexible extraction capabilities. You can specify the mode of operation for an extractor by using the mode field. The supported modes are:
| Mode | Description | Configuration validation |
|---|---|---|
EXTRACT (default) |
Extract the value of the specified capturing group from the source. This is the standard behavior of extractors prior to this version. The regex expression must match the entire source. Only the value in the specified subgroup is extracted. |
If the extractor mode is set to Extract, the replacement_text must not be set. If set, the configuration is rejected. |
SINGLE_REPLACE |
Replace the value of the n-th capturing group, where n is the value selected by subgroup, with the text specified in replacement_text. The regex expression must match the entire source for the replacement to work. The subgroup specifies which part of the match to replace. |
The replacement_text must be set. If not set, the configuration is rejected. |
REPLACE_ALL |
Replace all occurrences of the pattern specified in the regex field within the source with the text specified in replacement_text. The regex can match any part of the source. All matches are replaced. |
The subgroup field must not be set. If set, the configuration is rejected. In addition, the replacement_text must be set. If not set, the configuration is rejected. |
Extractor Example - Single Replace Mode
Define an extractor that replaces the first occurrence of the item banana with orange in a list of fruits. The exact composition of the list is unknown, but the format is the same, such as a comma-separated list.
Fruits: [apple, pear, banana, pineapple, etc.]
extractors:
BananaToOrange:
body: {}
mode: SINGLE_REPLACE
replacement_text: 'orange'
regex: '.*(banana).*'
subgroup: 1
body:
text: '{{ BananaToOrange }}'
In this configuration:
BananaToOrangeis the name of the extractor.body: {}indicates that the request/response body will be used as input to the extractor.regex: '.*(banana).*'is designed to match the entire source, and capture the wordbananain the first capturing group.mode: SINGLE_REPLACEspecifies the operation mode, indicating a single replace operation.replacement_text: 'orange'replaces the content in the first capturing group with the textorange.subgroup: 1specifies that the replacement should only apply to the first captured group, which is banana in this case.body.textadds the string with thereplacement_texttext back to the body.
In this case, if the extractor processes a body containing the text Fruits: [apple, pear, banana, pineapple]
The result will be Fruits: [apple, pear, orange, pineapple]
Extractor Example - Replace All Mode
Define an extractor that replaces all occurrences of the pattern foo with the text bar in the source.
extractors:
FooToBar:
body: {}
regex: 'foo'
mode: REPLACE_ALL
replacement_text: 'bar'
body:
text: '{{ FooToBar }}'
In this configuration:
FooToBaris the name of the extractor.body: {}indicates that the request/response body will be used as input to the extractor.regex: 'foo'specifies the pattern to match.mode: REPLACE_ALLspecifies the mode of operation.replacement_text: 'bar'specifies the text to replace the matched pattern with.body.textadds the string with thereplacement_texttext back to the body.
In this case, if the extractor processes a body containing the text foo foo foo, the result will be bar bar bar.
headers
Use this attribute to apply templates to request/response headers. It consists of a map where each key determines the name of the resulting header, while the corresponding value is a template which will determine the value.
For example, to set the header foo to the value of the header bar, you could use the following configuration:
transformationTemplate:
headers:
foo:
text: '{{ header("bar") }}'
You could also use the parsed data from the body and add information to the header. For instance, given a request body:
{
"Name": "Gloo",
"Favorites": {
"Color": "Blue"
}
}
You could reference the value stored in Color and place it into the headers like so:
transformationTemplate:
headers:
color:
text: '{{ Favorites.Color }}'
See the template language section for more details about template strings.
body
Use this attribute to apply templates to the request/response body. It consists of a template string that will determine the content of the resulting body.
As an example, the following configuration snippet could be used to transform a response body only if the HTTP response code is 404 and preserve the original response body in other cases.
transformationTemplate:
# [...]
body:
text: '{% if header(":status") == "404" %}{ "error": "Not found!" }{% else %}{{ body() }}{% endif %}'
# [...]
See the template language section for more details about template strings.
passthrough
In some cases your do not need to transform the request/response body nor extract information from it. In these cases, particularly if the payload is large, you should use the passthrough attribute to instruct Gloo Edge to ignore the body (i.e. to not buffer it). The attribute always takes just the empty value:
transformationTemplate:
# [...]
passthrough: {}
# [...]
If you’re looking to parse the body, and either ignore errors on parsing, or just disable JSON parsing, see those sections in this document, respectively.
mergeExtractorsToBody
Use this type of body transformation to merge all the extractions defined in the transformationTemplate to the body. The values of the extractions will be merged to a location in the body JSON determined by their names. You can use separators in the extractor names to nest elements inside the body.
For an example, see the following configuration:
transformationTemplate:
mergeExtractorsToBody: {}
extractors:
path:
header: ':path'
regex: '.*'
# The name of this attribute determines where the value will be nested in the body
host.name:
header: 'host'
regex: '.*'
This will cause the resulting body to include the following extra attributes (in additional to the original ones):
{
"path": "/the/request/path",
"host": {
"name": "value of the 'host' header"
}
}
dynamicMetadataValues
This attribute can be used to define an Envoy Dynamic Metadata entry. This metadata can be used by other filters in the filter chain to implement custom behavior.
As an example, the following configuration creates a dynamic metadata entry in the com.example namespace with key foo and value equal to that of the foo header.
dynamicMetadataValues:
- metadataNamespace: "com.example"
key: 'foo'
value:
text: '{{ header("foo") }}'
The metadataNamespace is optional. It defaults to the namespace of the Gloo Edge transformation filter name, i.e. io.solo.transformation.
A common use case for this attribute is to define custom data to be included in your access logs. See the dedicated tutorial for an example of how this can be achieved.
advancedTemplates
This attribute determines which notation to use when accessing elements in JSON structures. If set to true, Gloo Edge will expect JSON pointer notation (e.g. “time/start”) instead of dot notation (e.g. “time.start”). Defaults to false.
If set to true, you must use the extraction function to access extractors in template strings, such as {{ extraction("myExtractor") }}. If set to false (default), you must reference extractors in template strings by name only, such as {{ myExtractor }}.
escapeCharacters
This attribute is used to set for the entire transformation whether Inja should be configured to preserve escaped characters in strings. This is particularly useful when using context from the request or response body to construct new JSON bodies.
Templating language
Unless parseBodyBehavior is set to DontParse, templates can be used only if the request/response payload is a JSON string.
Gloo Edge templates are powered by v3.4 of the Inja template engine, which is inspired by the popular Jinja templating language in Python. When writing your templates, you can take advantage of all the core Inja features, i.a. loops, conditional logic, and functions.
In addition to the standard functions available in the core Inja library, you can use additional custom functions that we have added:
header(header_name): returns the value of the header with the given name.extraction(extractor_name): returns the value of the extractor with the given name.env(env_var_name): returns the value of the environment variable with the given name.body(): returns the request/response body.context(): returns the base JSON context (allowing for example to range on a JSON body that is an array).request_header(header_name): return the value of the request header with the given name. Useful for including request header values in response transformations.base64_encode(string): encodes the input string to base64.base64_decode(string): decodes the input string from base64.substring(string, start_pos, substring_len): returns a substring of the input string, starting atstart_posand extending forsubstring_lencharacters. If nosubstring_lenis provided orsubstring_lenis <= 0, the substring extends to the end of the input string.replace_with_random(string, pattern): returns the input string with instances matching thepatternreplaced with random characters.raw_string(string): returns the input string with escaped characters intact. Useful for constructing JSON request or response bodies.
You can use templates to mutate headers, the body, and dynamic metadata.
XSLT Transformation
XSLT transformations
allow transformations on HTTP requests using the XSLT transformation language.
The following snippet illustrates the structure of the xsltTransformation object.
xsltTransformation:
xslt: string
setContentType: string
nonXmlTransform: bool
xslt
The XSLT transformation is specified in this field as a string. Like other transformations, an invalid XSLT transformation will not be accepted and envoy validation will reject the transformation configuration.
setContentType
XSLT transformations can be used to transform HTTP body between content type. For example, from XML to JSON, or JSON to XML.
In the case of these transformations, the content-type HTTP header is set to the value of setContentType. If left empty, the content-type header is unchanged.
nonXmlTransform
XSLT transformations typically accept only XML as input. If the input to the transformation is not XML, this should be set to true. For example, if
the XSLT transformation is transforming a JSON input to XML, this would be set to true. By default, this is false and the XSLT transformation will only accept XML input.
Common use cases
On this page we have seen all the properties of the Gloo Edge Transformation API as well as some simple example snippets. If are looking for complete examples, please check out the following tutorials, which will guide you through some of the most common transformation use cases.
-
Change response status: Conditionally update the status of an HTTP response
-
Decode and modify base64 request headers: Decode and modify base64 encoded request headers before forwarding the requests upstream.
-
Inject response header: Inject request headers into response
-
SOAP/XSLT transformation (Enterprise): Transforming the request body from SOAP/XML to a JSON.
-
Extract query parameters: Extract query parameters from a request
-
Update request path: Conditionally update the request path
-
Add headers to the body: Adding request/response headers to the body
-
Debug logging for transformations: Debug complex sequences of transformations.
-
Enriching access logs: Use transformations to craft custom attributes in access logs.